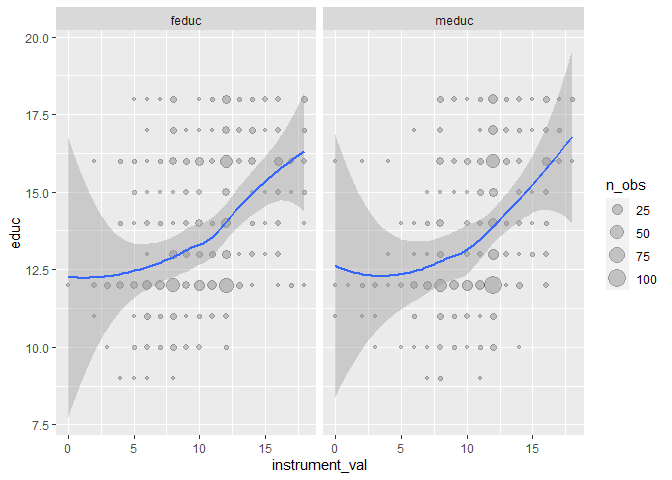
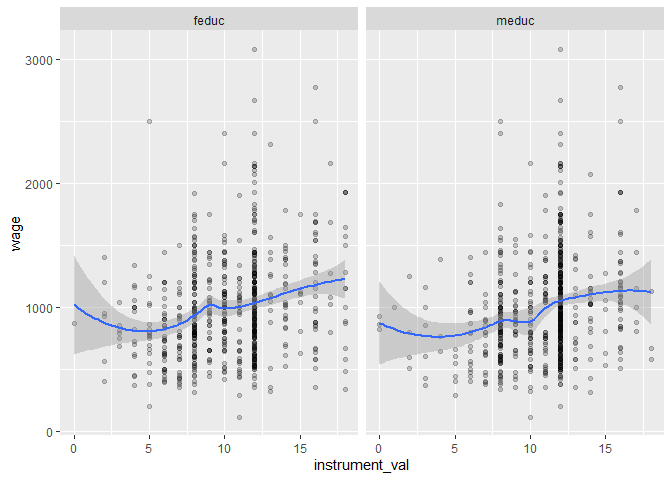
ggplot(ed_real_long, aes(x=instrument_val, y = wage))+ geom_point(alpha =0.2)+ geom_smooth(method ='loess', formula ='y ~ x')+ facet_wrap(vars(instrument))
Exogeneity
There's no statistical test for exogeneity.
Scott Cunningham's argument
The reason I think this is because an instrument doesn’t belong in
the structural error term and the structural error term is all the
intuitive things that determine your outcome. So it must be weird,
otherwise it's probably in the error term.
2-Stage Least Squares (2SLS)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# Conduct 2SLS manually first_stage <- lm(educ ~ feduc + meduc + hours + exper + tenure + age + married + black + south + urban + sibs + brthord, data = ed_real) ed_real_with_pred <- copy(ed_real) ed_real_with_pred$educ_hat <- first_stage$fitted.values second_stage <- lm(wage ~ educ_hat + hours + exper + tenure + age + married + black + south + urban + sibs + brthord, data = ed_real_with_pred)
# Conduct 2SLS automatically model_2sls <- estimatr::iv_robust(wage ~ educ + hours + exper + tenure + age + married + black + south + urban + sibs + brthord | feduc + meduc + hours + exper + tenure + age + married + black + south + urban + sibs + brthord, data = ed_real, diagnostics =TRUE)
Notes: A test of overidentifying restrictions
regresses the residuals from an
IV or 2SLS regression on all instruments in . Under the null
hypothesis, all instruments are uncorrelated with .
The test of overidentifying restrictions should be performed
routinely in any overidentified model estimated with instrumental
variables techniques. Instrumental variables techniques are powerful,
but if a strong rejection of the null hypothesis is encountered, you
should strongly doubt the validity of the estimates.
Practice 5:
Complier Average Treatment Effects
We can calculate conditional average treatment effect (CATE) by
averaging the treatment effect of a program over some segment of the
population.
One important type of CATE is the effect of a program on just those
who comply with the program. This is the complier average treatment
effect, but the acronym would be the same as the conditional average
treatment effect, so we call it the complier average causal
effect (CACE), also known as the local average
treatment effect (LATE).
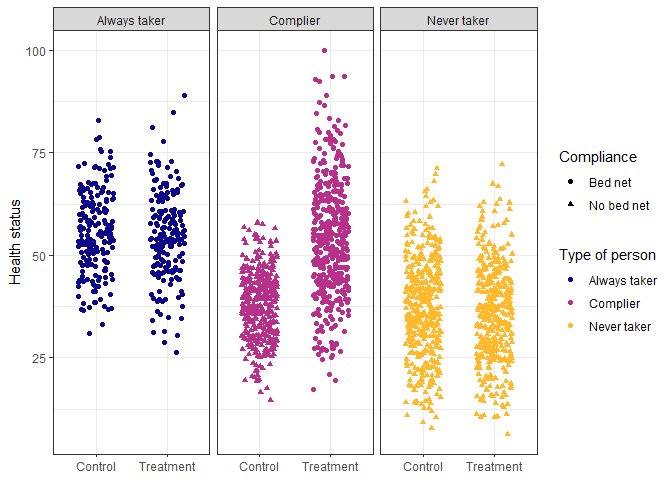
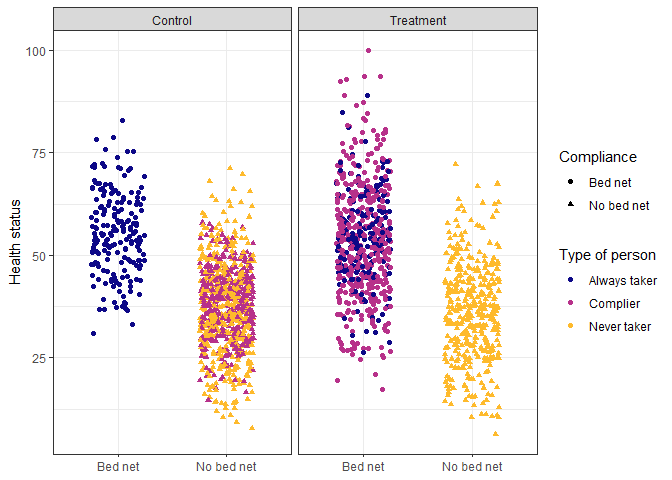
We can split the population into four types of people:
Compliers: People who follow whatever their
assignment is
Always takers: People who will receive or seek out
the treatment regardless of assignment
Never takers: People who will NOT receive or seek
out the treatment regardless of assignment
Defiers: People who will do the opposite of
whatever their assignment is
For simplicity, we assume that defiers don’t exist based on the idea
of monotonicity, which means that the effect of being assigned
to treatment only increases the likelihood of participating in the
program rather than decreases.
Ideally, we can identify different types of people from the data.
However, we can tell some of the always takers from the control group
(those who used bed nets after being assigned to the control group) and
some of the never takers from the treatment group (those who did not use
a bed net after being assigned to the treatment group), but compliers
are mixed up with the always and never takers.
Intent to Treat (ITT)
We can calculate ITT by assuming the proportion of compliers (c),
never takers (n), and always takers (a) are equally spread across
treatment and control. This assumption is plausible in a randomized
control trial.
Suppose treatment doesn’t make someone more likely to be an always
taker or a never taker, we have and . Hence,
## treatment bed_net N percent ## 1: Control Bed net 196 0.1952 ## 2: Control No bed net 808 0.8048 ## 3: Treatment Bed net 608 0.6104 ## 4: Treatment No bed net 388 0.3896
model_2sls <- estimatr::iv_robust(health ~ as.factor(bed_net)| as.factor(treatment), data = bed_nets_time_machine) round(summary(model_2sls)$coef,2)
1 2 3 4 5 6
## Estimate Std. Error t value Pr(>|t|) CI Lower ## (Intercept) 52.54 0.84 62.2 0 50.89 ## as.factor(bed_net)No bed net -14.42 1.25 -11.5 0 -16.88 ## CI Upper DF ## (Intercept) 54.20 1998 ## as.factor(bed_net)No bed net -11.96 1998

View / Make Comments