lm(malaria_risk ~ household + net + health + income + temperature, data = nets)%>% (function(x) summary(x)$coeff)%>% (function(x)round(x,4))
1 2 3 4 5 6 7
## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 76.2067 0.9658 78.9062 0.0000 ## household -0.0155 0.0893 -0.1730 0.8626 ## netTRUE -10.4370 0.2665 -39.1633 0.0000 ## health 0.1483 0.0107 13.8997 0.0000 ## income -0.0751 0.0010 -72.5635 0.0000 ## temperature 1.0058 0.0310 32.4829 0.0000
Notes: No correlation ⇏ Independence
[Example] Flip a fair coin to determine the amount of your bet: bet
$1 if heads $2 if tails. Then flip again: win the amount of your bet if
heads lose if tails.
Naive Comparison
1 2
model_naive <- lm(malaria_risk ~ net, data = nets) summary(model_naive)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
## ## Call: ## lm(formula = malaria_risk ~ net, data = nets) ## ## Residuals: ## Min 1Q Median 3Q Max ## -26.937 -9.605 -1.937 7.063 55.395 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 41.9365 0.4049 103.57 <2e-16 *** ## netTRUE -16.3315 0.6495 -25.15 <2e-16 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 13.25 on 1750 degrees of freedom ## Multiple R-squared: 0.2654, Adjusted R-squared: 0.265 ## F-statistic: 632.3 on 1 and 1750 DF, p-value: < 2.2e-16
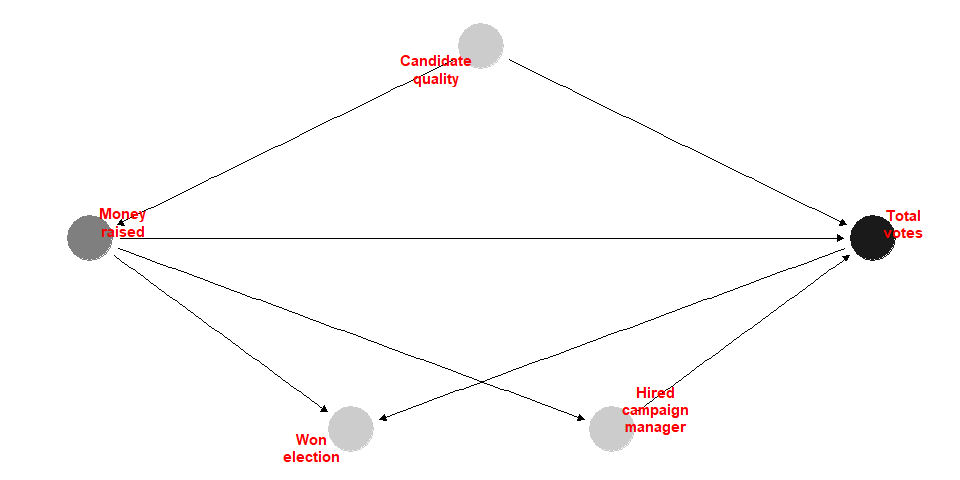
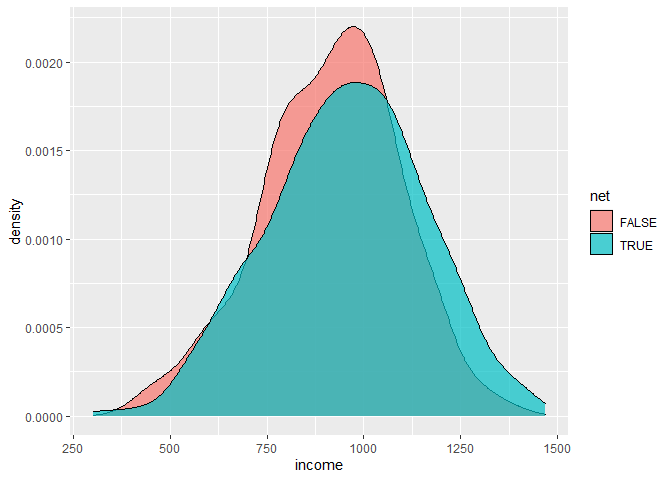
## ## Welch Two Sample t-test ## ## data: income by net ## t = -8.8113, df = 1284.7, p-value < 2.2e-16 ## alternative hypothesis: true difference in means between group FALSE and group TRUE is not equal to 0 ## 95 percent confidence interval: ## -100.79660 -64.08593 ## sample estimates: ## mean in group FALSE mean in group TRUE ## 872.7526 955.1938
1 2 3 4 5 6 7 8 9 10 11
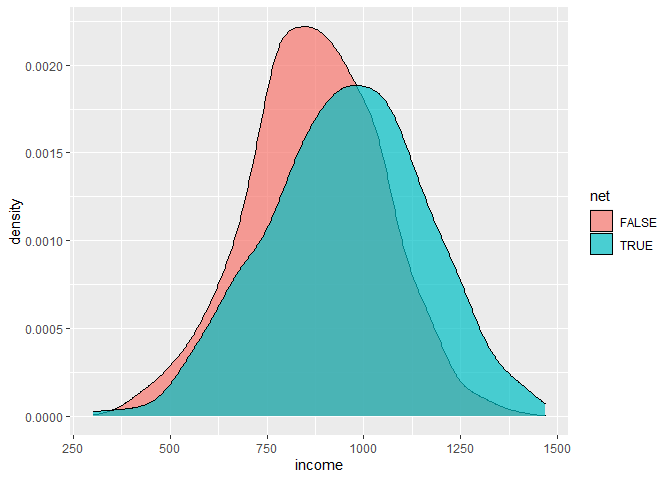
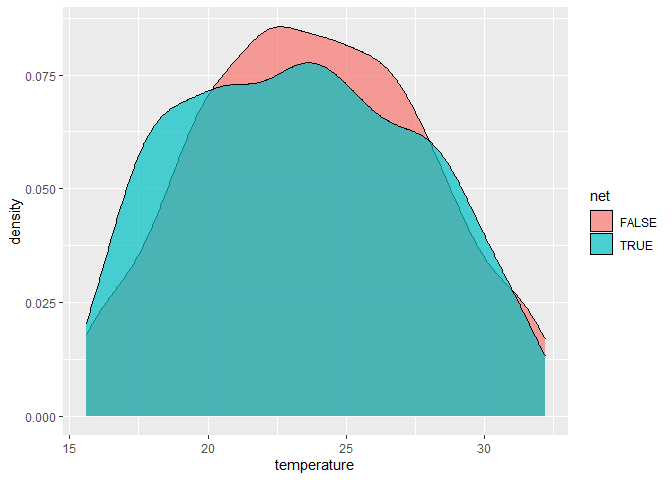
## ## Welch Two Sample t-test ## ## data: temperature by net ## t = 3.492, df = 1404.3, p-value = 0.0004943 ## alternative hypothesis: true difference in means between group FALSE and group TRUE is not equal to 0 ## 95 percent confidence interval: ## 0.3098586 1.1042309 ## sample estimates: ## mean in group FALSE mean in group TRUE ## 24.08796 23.38091
1 2 3 4 5 6 7 8 9 10 11
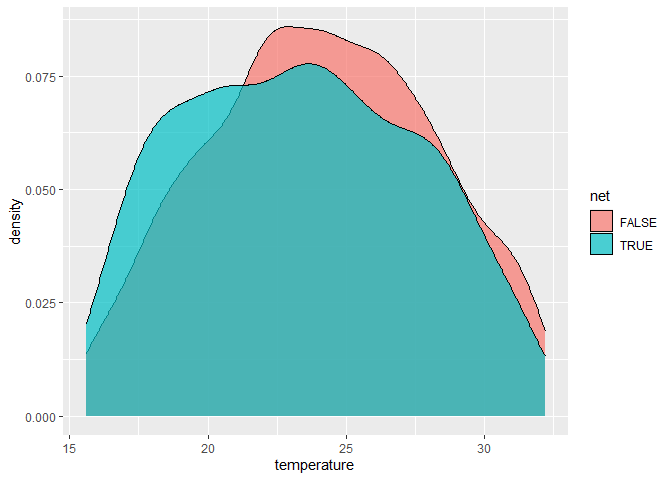
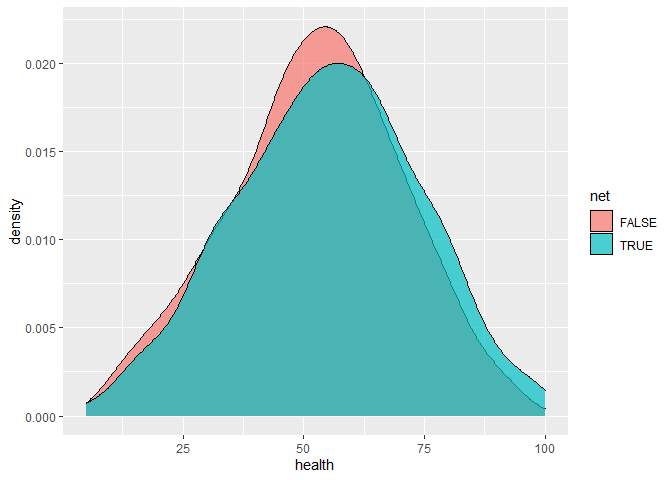
## ## Welch Two Sample t-test ## ## data: health by net ## t = -7.6447, df = 1346.9, p-value = 3.961e-14 ## alternative hypothesis: true difference in means between group FALSE and group TRUE is not equal to 0 ## 95 percent confidence interval: ## -8.610309 -5.093693 ## sample estimates: ## mean in group FALSE mean in group TRUE ## 48.05696 54.90896
Regression
1 2
model_regression <- lm(malaria_risk ~ net + income + temperature + health, data = nets) summary(model_regression)
## ## Call: ## lm(formula = malaria_risk ~ net + income + temperature + health, ## data = nets) ## ## Residuals: ## Min 1Q Median 3Q Max ## -13.143 -3.915 -0.561 3.333 16.461 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 76.159901 0.926835 82.17 <2e-16 *** ## netTRUE -10.441932 0.264906 -39.42 <2e-16 *** ## income -0.075144 0.001035 -72.58 <2e-16 *** ## temperature 1.005855 0.030953 32.50 <2e-16 *** ## health 0.148362 0.010668 13.91 <2e-16 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 5.244 on 1747 degrees of freedom ## Multiple R-squared: 0.8852, Adjusted R-squared: 0.8849 ## F-statistic: 3366 on 4 and 1747 DF, p-value: < 2.2e-16
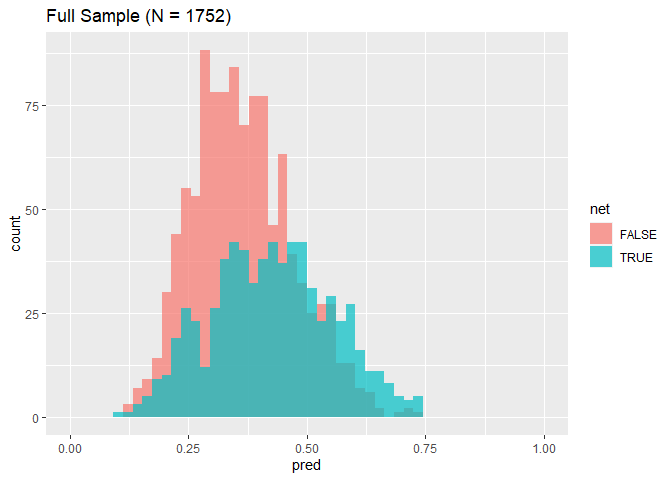
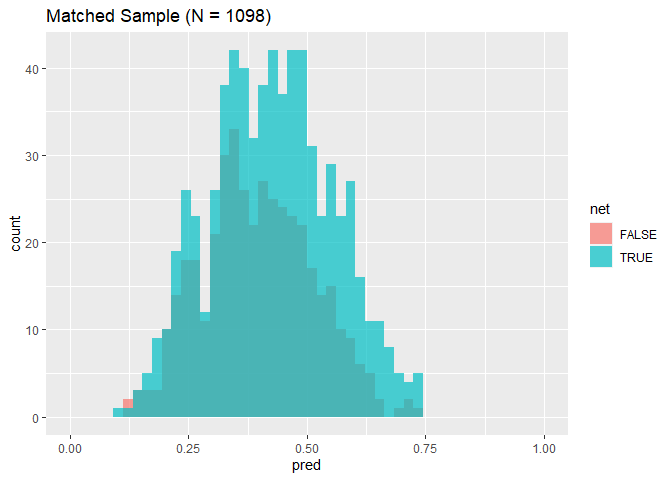
Matching (Mahalanobis
Distance)
Mahalanobis distance between and
where is the covariance
matrix.
1 2 3 4 5 6 7
library(MatchIt)
matched <- matchit(net ~ income + temperature + health, data = nets, method ="nearest", distance ="mahalanobis", replace =TRUE) matched
1 2 3 4 5 6
## A matchit object ## - method: 1:1 nearest neighbor matching with replacement ## - distance: Mahalanobis ## - number of obs.: 1752 (original), 1120 (matched) ## - target estimand: ATT ## - covariates: income, temperature, health
1 2
# Dimension of the data used for matching dim(matched$X)
1
## [1] 1752 3
1 2
# Number of the treated sum(matched$treat)
1
## [1] 681
1 2
# Number of the matched control sum(matched$weights>0)
1
## [1] 1120
1 2
# Number of the unmatched control sum(matched$weights==0)
1
## [1] 632
The matchit() function determines the pair weights by
measuring how close the matched pair are. The weights can be used in the
regression to account for the variation in distance.
## ## Welch Two Sample t-test ## ## data: income by net ## t = -3.5017, df = 990.87, p-value = 0.0004829 ## alternative hypothesis: true difference in means between group FALSE and group TRUE is not equal to 0 ## 95 percent confidence interval: ## -64.12955 -18.06677 ## sample estimates: ## mean in group FALSE mean in group TRUE ## 914.0957 955.1938 ## ## ## Welch Two Sample t-test ## ## data: temperature by net ## t = 0.79239, df = 952.76, p-value = 0.4283 ## alternative hypothesis: true difference in means between group FALSE and group TRUE is not equal to 0 ## 95 percent confidence interval: ## -0.2955968 0.6959627 ## sample estimates: ## mean in group FALSE mean in group TRUE ## 23.58109 23.38091 ## ## ## Welch Two Sample t-test ## ## data: health by net ## t = -3.0287, df = 977.39, p-value = 0.002521 ## alternative hypothesis: true difference in means between group FALSE and group TRUE is not equal to 0 ## 95 percent confidence interval: ## -5.567087 -1.189325 ## sample estimates: ## mean in group FALSE mean in group TRUE ## 51.53075 54.90896
## ## Welch Two Sample t-test ## ## data: income by net ## t = -3.548, df = 954.79, p-value = 0.0004071 ## alternative hypothesis: true difference in means between group FALSE and group TRUE is not equal to 0 ## 95 percent confidence interval: ## -64.64167 -18.59971 ## sample estimates: ## mean in group FALSE mean in group TRUE ## 913.5731 955.1938
1 2 3 4 5 6 7 8 9 10 11
## ## Welch Two Sample t-test ## ## data: temperature by net ## t = 1.4522, df = 910.52, p-value = 0.1468 ## alternative hypothesis: true difference in means between group FALSE and group TRUE is not equal to 0 ## 95 percent confidence interval: ## -0.1294926 0.8664727 ## sample estimates: ## mean in group FALSE mean in group TRUE ## 23.74940 23.38091
1 2 3 4 5 6 7 8 9 10 11
## ## Welch Two Sample t-test ## ## data: health by net ## t = -2.1015, df = 920.12, p-value = 0.03587 ## alternative hypothesis: true difference in means between group FALSE and group TRUE is not equal to 0 ## 95 percent confidence interval: ## -4.6145611 -0.1577902 ## sample estimates: ## mean in group FALSE mean in group TRUE ## 52.52278 54.90896
Inverse Probability
Weighting
1 2 3 4 5 6 7 8 9 10
# Predict the probability of a household using bed nets model_treatment <- glm(net ~ income + temperature + health, data = nets, family = binomial(link ="logit")) nets_ipw <- copy(nets) nets_ipw$pred <- model_treatment$fitted.values nets_ipw[, ipw :=(net_num / pred)+(1- net_num)/(1- pred)]
# Evaluate the effect with inverse probability weights model_ipw <- lm(malaria_risk ~ net, data = nets_ipw, weights = ipw) summary(model_ipw)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
## ## Call: ## lm(formula = malaria_risk ~ net, data = nets_ipw, weights = ipw) ## ## Weighted Residuals: ## Min 1Q Median 3Q Max ## -45.705 -14.622 -4.924 10.791 162.642 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 39.6788 0.4684 84.71 <2e-16 *** ## netTRUE -10.1312 0.6583 -15.39 <2e-16 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 19.54 on 1750 degrees of freedom ## Multiple R-squared: 0.1192, Adjusted R-squared: 0.1187 ## F-statistic: 236.8 on 1 and 1750 DF, p-value: < 2.2e-16
Inverse Probability Weights
Think of this formula in a controlled experiment scenario:
Individuals are more likely to be never-takers
(in a control group) if their likelihood values of receiving treatment
are lower than the average and they do not receive
treatment
Individuals are more likely to be always-takers
(in a treatment group) if their likelihood values of receiving treatment
are higher than the average and they do receive
treatment
Individuals are more likely to be compliers (in
both the control and the treatment group) if their likelihood values of
receiving treatment are inconsistent with their actual
treatment
To the end, we evaluate the change in the compliers' outcomes due to
their different exposures to the treatment.
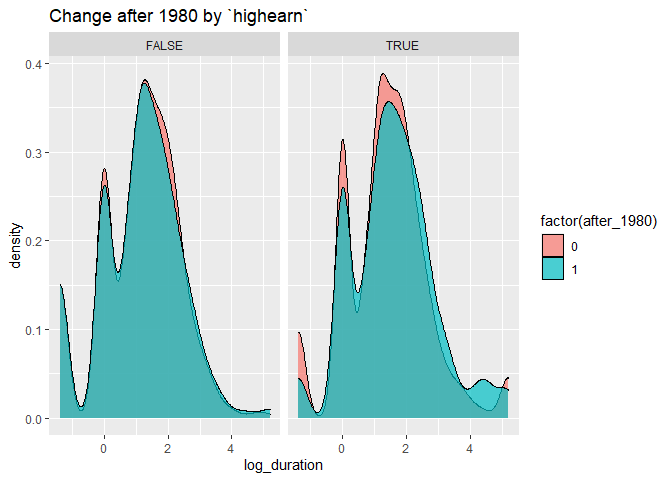
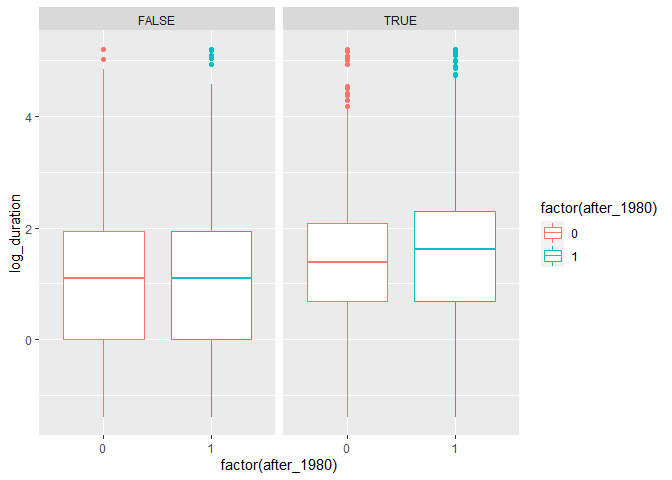
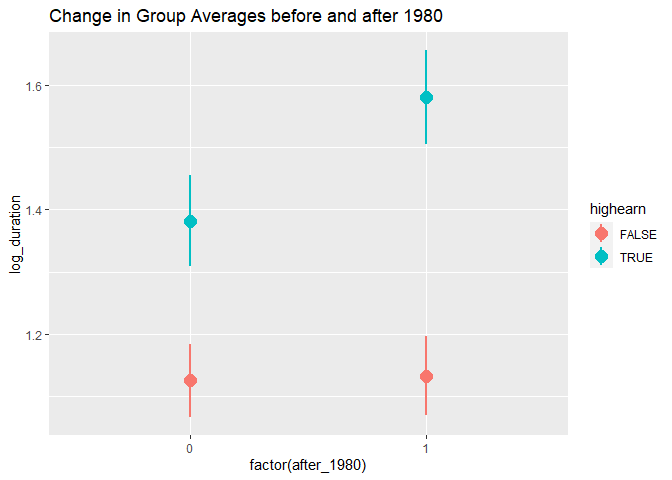
Background (Wooldridge’s Intro Econometrics P411): Meyer, Viscusi,
and Durbin (1995) (hereafter, MVD) studied the length of time (in weeks)
that an injured worker receives workers’ compensation. On July 15, 1980,
Kentucky raised the cap on weekly earnings that were covered by workers’
compensation. An increase in the cap has no effect on the benefit for
low-income workers, but it makes it less costly for a high-income worker
to stay on workers’ compensation. Therefore, the control group is
low-income workers, and the treatment group is high-income workers;
high-income workers are defined as those who were subject to the
pre-policy change cap. Using random samples both before and after the
policy change, MVD were able to test whether more generous workers’
compensation causes people to stay out of work longer (everything else
fixed). They started with a difference-in-differences analysis, using
log(durat) as the dependent variable. Let afchnge be the dummy variable
for observations after the policy change and highearn the dummy variable
for high earners.


View / Make Comments