How to detect a distribution for a set of data points? When it comes
to this question, we don't spend a second creating a histogram or a
density plot to visualize the distribution of the given data points. If
there are some potential distributions to be compared, we can add their
PDF curves to the existing plot or create a QQ plot. That is it. We then
move forward.
I didn't think of this question carefully until I failed an
interview. Unfortunately, after saying we could detect the distribution
by visualizing a density plot, I was expected to propose a test
statistic. I vaguely remembered the rationale of the Kolmogorov-Smirnov
(KS) Test but forgot the name. Although I found the KS statistic after
the interview, I was still wondering if there was another simple test.
My Eureka moment appeared when I watched a YouTube video about the
Chi-squared Test. Yes, we can also compare the distributions from two
sets of data points using the Chi-squared Test.
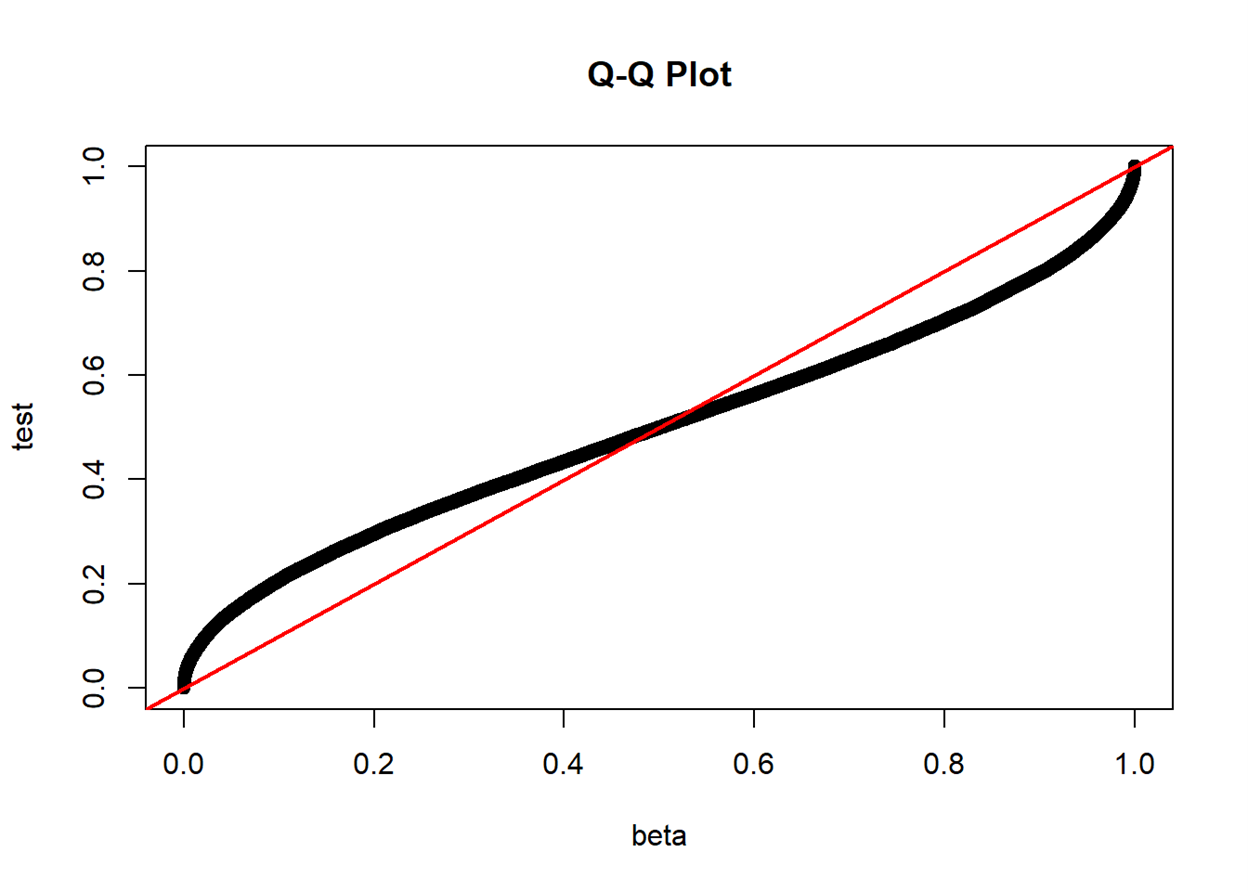
"In statistics, a Q–Q
plot (quantile-quantile plot) is a probability
plot, a graphical method for comparing
two probability distributions by plotting their quantiles
against each other. A point (x, y) on the plot
corresponds to one of the quantiles of the second distribution
(y-coordinate) plotted against the same quantile of the first
distribution (x-coordinate)." -- Wikipedia
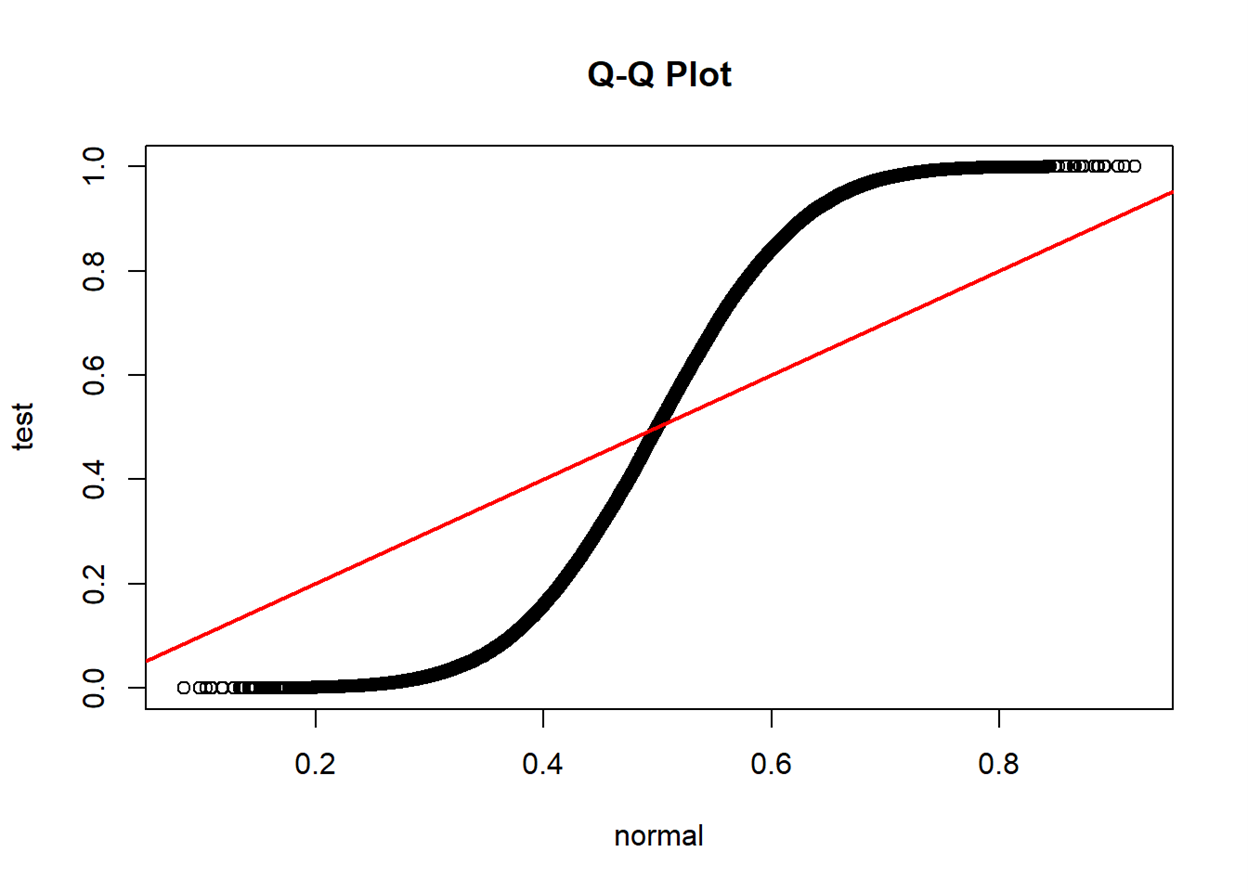
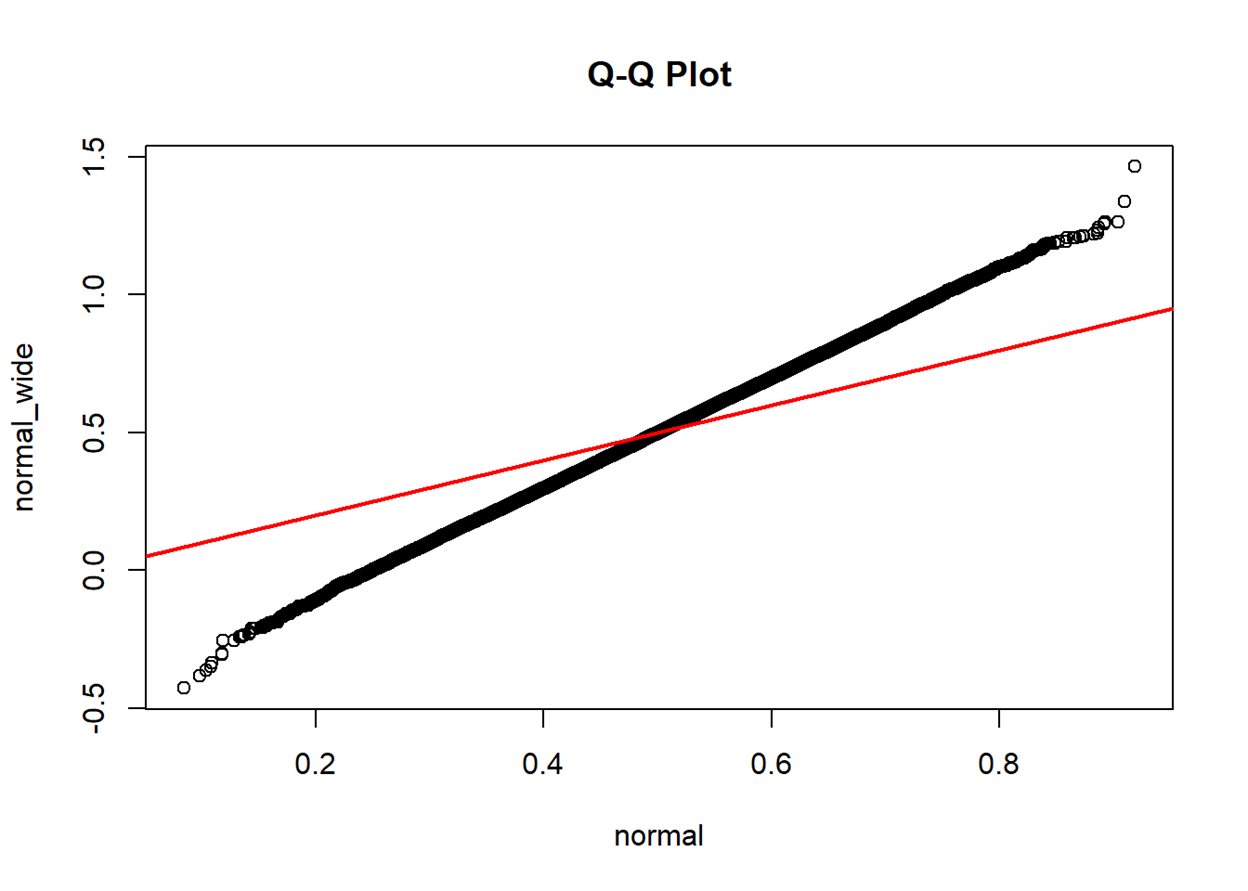
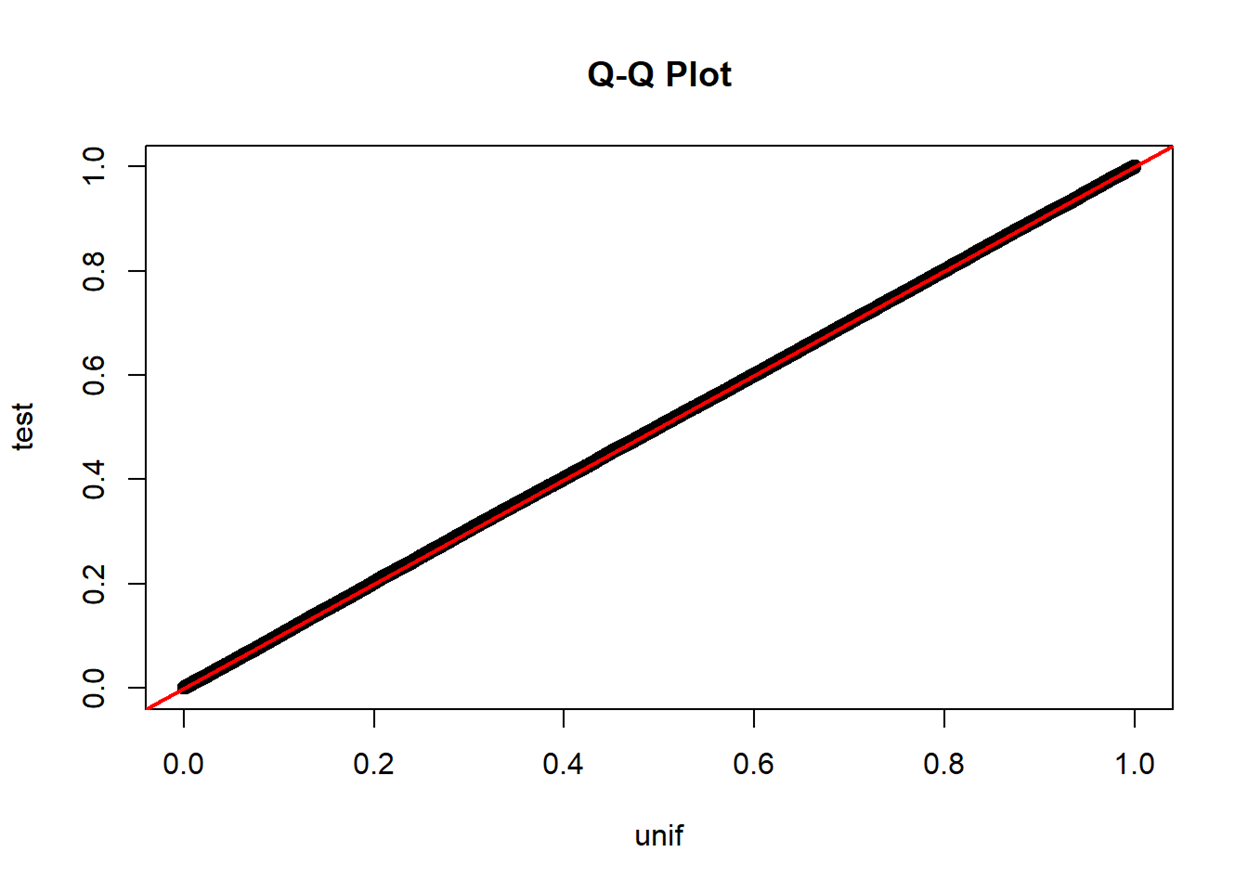
If two distributions are similar, the points in the Q–Q plot will
approximately lie on the identity line
If two distributions are similar, the points in the Q–Q plot will
approximately lie on a line, parallel to the identity line
A Q-Q plot also sheds light on the shift of location parameters
(e.g., how the median point in the test set locates in the point set
from a known distribution) and the change in scale parameters (e.g., how
the standard deviation of the test set differs from that of the standard
normal)
Kolmogorov–Smirnov Test
"In statistics, the Kolmogorov–Smirnov
test (K–S test or KS test) is
a nonparametric
test of the equality of continuous,
one-dimensional probability distributions that can be used to
compare a sample with a reference probability distribution (one-sample
K–S test) or to compare two samples (two-sample K–S test)." -- Wikipedia
The Kolmogorov–Smirnov test may also be used to test whether two
underlying one-dimensional probability distributions differ.
where and are the empirical distribution
functions of the first and the second sample respectively.
Illustration of the two-sample Kolmogorov–Smirnov statistic. Red and
blue lines each correspond to an empirical distribution function, and
the black arrow is the two-sample KS statistic.
For large samples, the null hypothesis is rejected at level if
where and are the sizes of the first and the
second sample respectively. The value of is given in the table
below:
## Two-sample Kolmogorov-Smirnov test ## ## data: df[dist == "unif"]$val and df[dist == "test"]$val ## D = 0.00356, p-value = 0.5506 ## alternative hypothesis: two-sided
Chi-squared Test
Suppose there are observations, classified into mutually exclusive groups with a
respective number (for ) of observations in the
th group. In the null hypothesis,
we assume an observation falls into the th group with a probability of , such that
As , the
limiting distribution of the quantity given below is the distribution with degrees of freedom:
for(dist_i inc('normal')){ cat('# ----', dist_i,'v.s. normal_wide ----') # test_group: length of val by number of cuts # Create a list of booleans for each value in the test sequence test_group <- sapply(df_cut[dist==dist_i]$cut_min,function(x) df[dist=='normal_wide']$val>x) # df_test: length of val by two =(aggregate by quant)=> number of cuts by two # Identify the cutoff group for each value and # Count the number of values in each cutoff group df_test <- data.table('quant'=rowSums(test_group),'normal_wide'=df[dist=='normal_wide']$val)[ , .(normal_wide=.N), by='quant'][order(quant)] # data_test: number of cuts by three (i.e., quant, dist_target, dist_test) # Combine target and test sequence by cutoff groups data_test <- merge(df_count[,c('quant', dist_i), with=FALSE], df_test, by='quant', all.x =TRUE) setnafill(data_test, fill =0) # Execute Chi-squared test print(chisq.test(data_test[,-1])) }





View / Make Comments